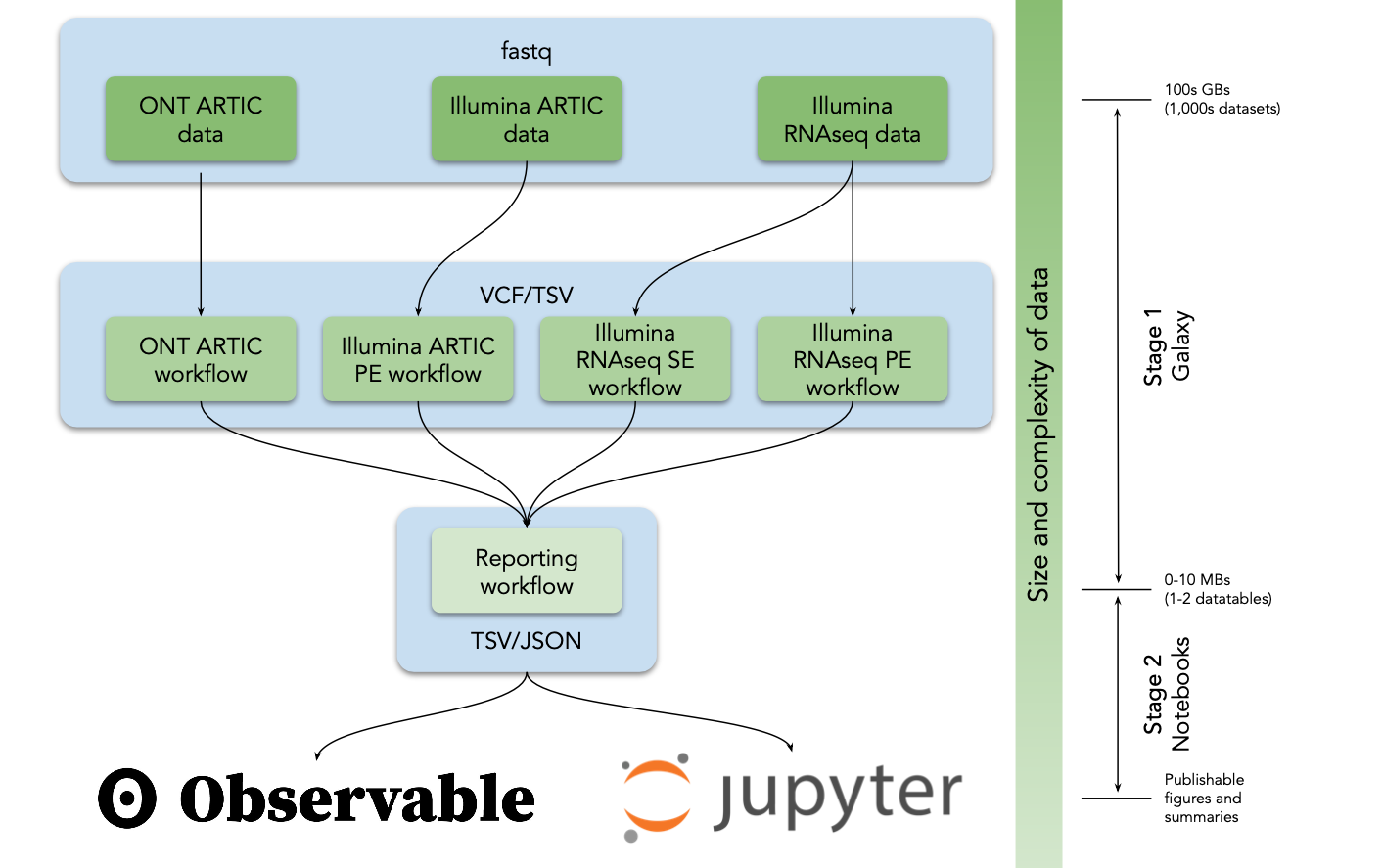
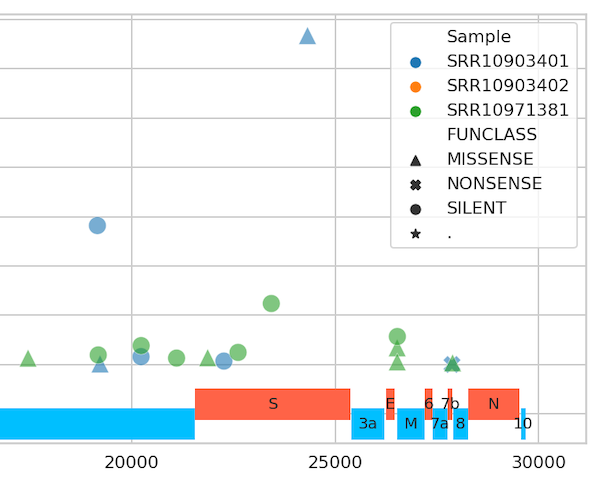
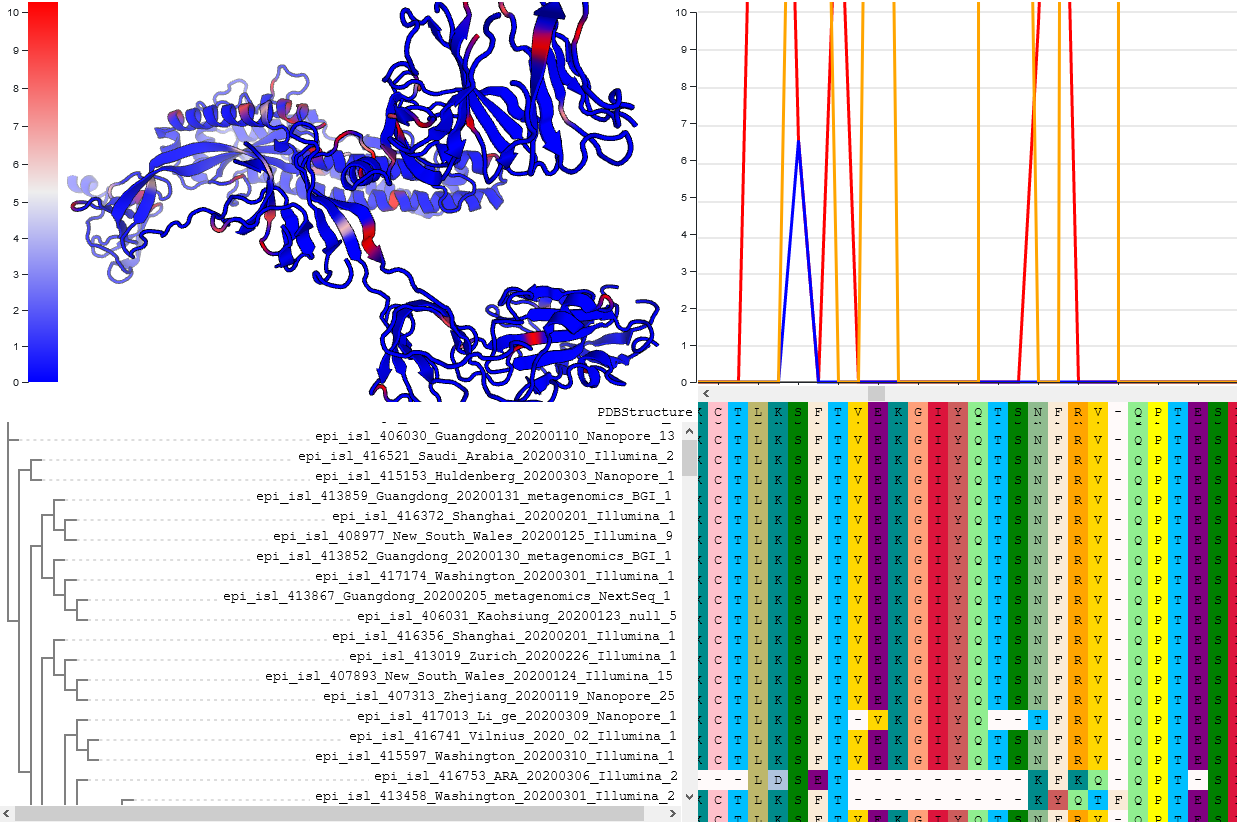
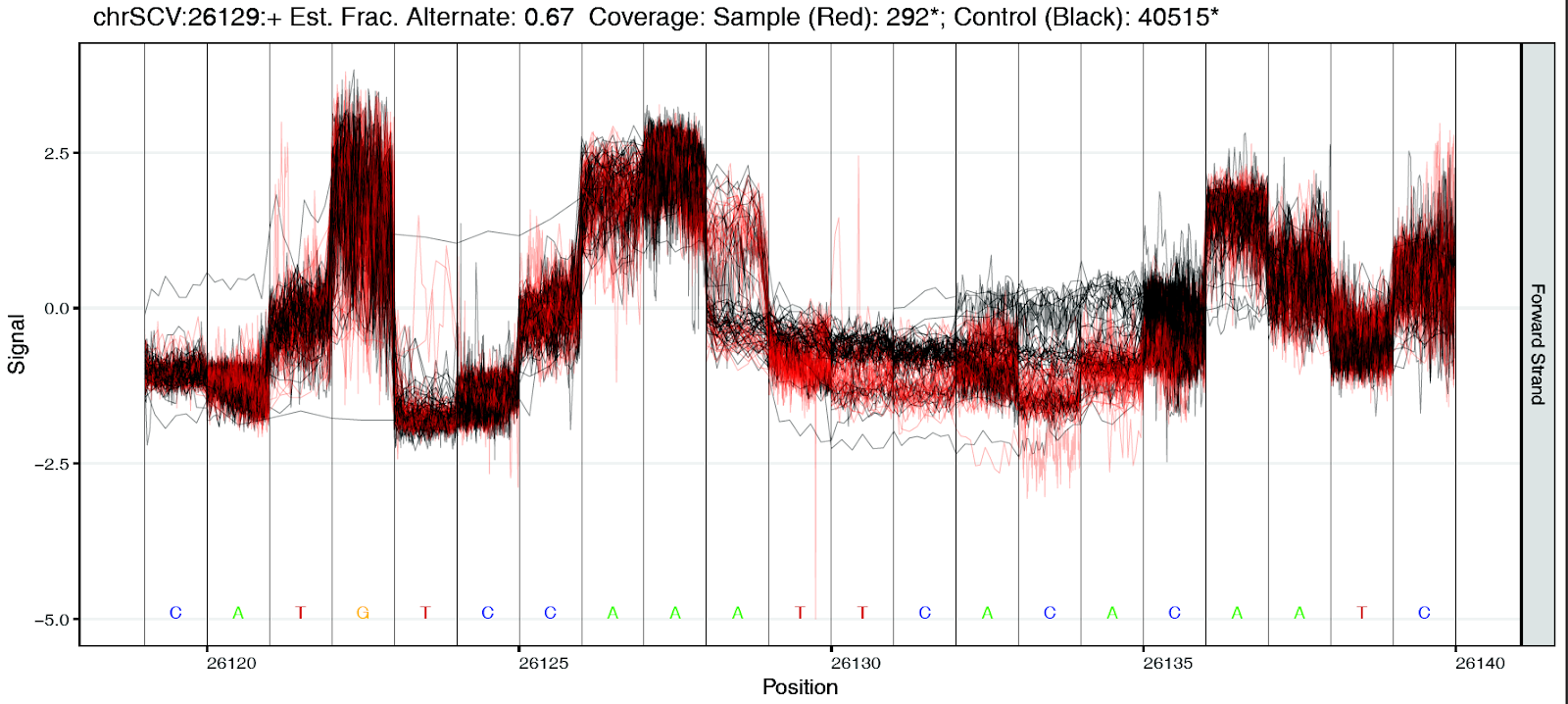
COVID-19 analysis on usegalaxy.★
Genomics
Cheminformatics
Proteomics
Data
Webinars
Edit on GitHub
(opens new window)
Global Platform
new
Freely accessible ready to use global infrastructure for SARS-CoV-2 monitoring
PLoS Pathogens 2020
No more business as usual: Agile and effective responses to emerging pathogen threats require open data and open analytics
Evolution
Sites under selection
Natural Selection Analysis
Analysis
Visualizations
Observable Notebooks
Artic
Amplicon based data analysis
direct RNA-seq
direct RNA-seq data analysis
Pre-Processing
RNA Epigenetics